How prioritized model load-balancing helps keep your AI-powered workloads running
Art Berger
May 2, 2025
When deploying workloads that rely on large language models (LLMs) in production, an important, yet often overlooked, challenge is LLM reliability. Models can go offline for all sorts of reasons: infrastructure hiccups, resource constraints, or version rollouts gone awry.
When that happens, your AI-powered workloads are left with no response. Especially in complex agentic setups that rely on several LLM interactions, such disruption can significantly impact the user experience.
With kgateway, you can set up prioritized model load-balancing to keep the LLM responses flowing.
What is model priority?
Model priority is the process of prioritizing models so that kgateway routes requests first to your preferred model. If that primary model becomes unavailable, starts returning errors, or can no longer be accessed, such as due to rate limits or tiered plan limits, you can further configure kgateway to failover to the next model.
What about load balancing?
Load balancing distributes incoming requests across multiple models by priority. This isn’t only about performance—it’s also a way to gracefully scale and prepare for sudden traffic spikes or partial failures.
How model priority and load balancing work together
- Load balancing helps distribute requests across healthy models
- Priority ensures that requests go first to your preferred, healthy model
Example scenario
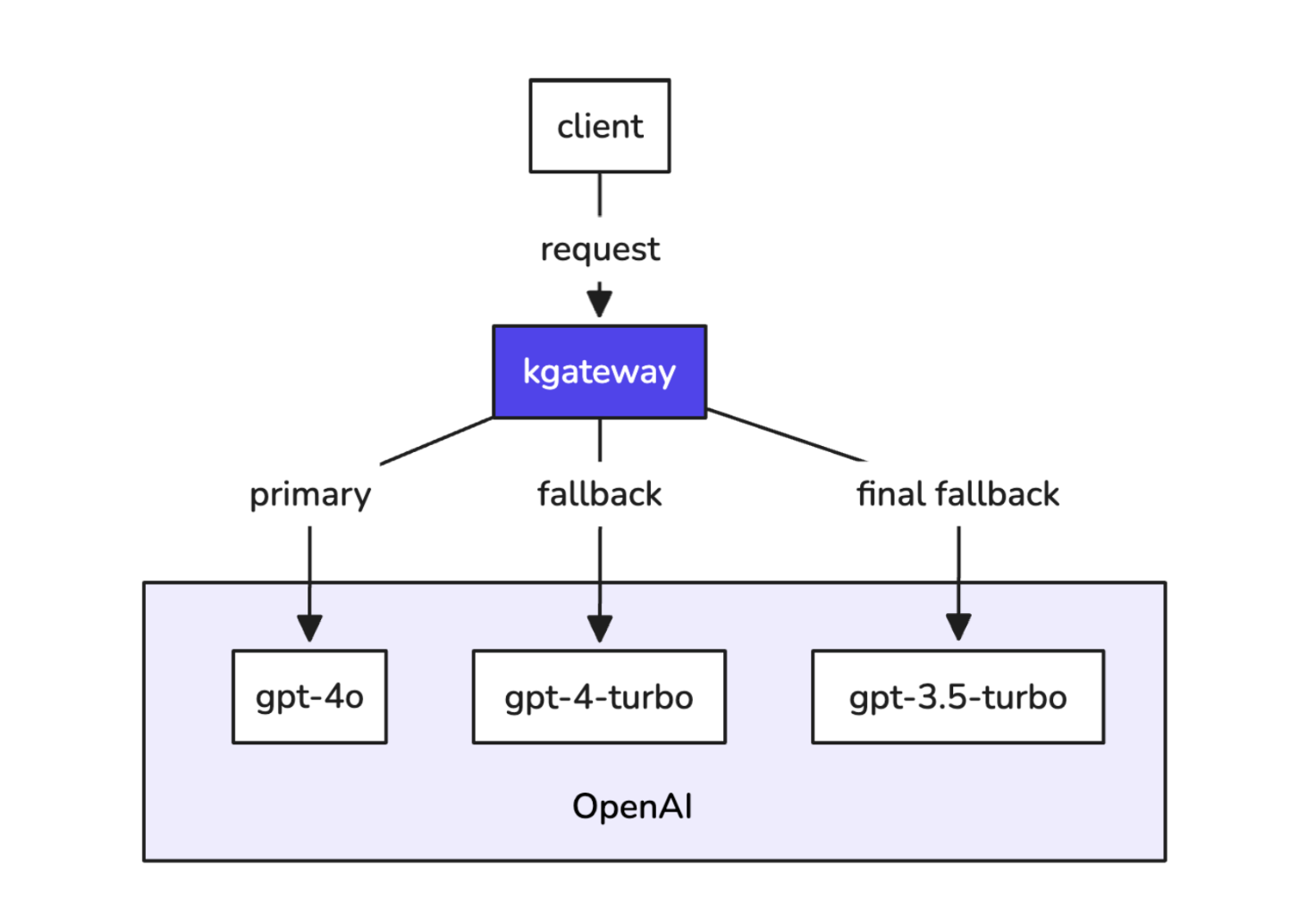
Let’s take a look at how we can set up model priority with kgateway. As shown in Figure 1, kgateway prioritizes requests across three models from the OpenAI LLM provider: the primary gpt-4o model and two fallback models, gpt-4-turbo and gpt-3.5-turbo.
Figure 1: Example of model priority with three OpenAI models. Source in Excalidraw.
Before you begin
Make sure that you have a basic kgateway environment set up with AI Gateway and your LLM provider. If you don’t, check out these docs:
Step 1: Create a Backend for your models
In kgateway, a Backend represents a service that you want to route traffic to. It includes special capabilities, including the ability to represent an AI backing service. The following Backend sets up a pool of models to route to in a prioritized order:
- gpt-4o model
- gpt-4.0-turbo model
- gpt-3.5-turbo model
kubectl apply -f- <<EOF
apiVersion: gateway.kgateway.dev/v1alpha1
kind: Backend
metadata:
labels:
app: model-priority
name: model-priority
namespace: kgateway-system
spec:
type: AI
ai:
priorityGroups:
- providers:
- openai:
model: "gpt-4o"
authToken:
kind: SecretRef
secretRef:
name: openai-secret
- openai:
model: "gpt-4.0-turbo"
authToken:
kind: SecretRef
secretRef:
name: openai-secret
- openai:
model: "gpt-3.5-turbo"
authToken:
kind: SecretRef
secretRef:
name: openai-secret
EOFkubectl apply -f- <<EOF
apiVersion: gateway.kgateway.dev/v1alpha1
kind: Backend
metadata:
labels:
app: model-priority
name: model-priority
namespace: kgateway-system
spec:
type: AI
ai:
multipool:
priorities:
- pool:
- provider:
openai:
model: "gpt-4o"
authToken:
kind: SecretRef
secretRef:
name: openai-secret
- pool:
- provider:
openai:
model: "gpt-4.0-turbo"
authToken:
kind: SecretRef
secretRef:
name: openai-secret
- pool:
- provider:
openai:
model: "gpt-3.5-turbo"
authToken:
kind: SecretRef
secretRef:
name: openai-secret
EOFStep 2: Create an HTTPRoute to the Backend
Create an HTTPRoute resource that routes incoming traffic on the /openai path to the Backend that you created in the previous step. AI Gateway automatically rewrites this path to the API path of a supported LLM, such as /v1/chat/completions in OpenAI.
The parent of the HTTPRoute is the AI Gateway that you created before you began. If you used a different Gateway, make sure to update the resource accordingly.
kubectl apply -f- <<EOF
apiVersion: gateway.networking.k8s.io/v1
kind: HTTPRoute
metadata:
name: model-priority
namespace: kgateway-system
labels:
app: model-priority
spec:
parentRefs:
- name: ai-gateway
namespace: kgateway-system
rules:
- matches:
- path:
type: PathPrefix
value: /openai
backendRefs:
- name: model-priority
namespace: kgateway-system
group: gateway.kgateway.dev
kind: Backend
EOFStep 3: Try it out
Now that you have the routing set up to your AI Backend’s pool of models, it’s time to try out a request.
Get the IP address of your AI Gateway, such as with the following command.
export INGRESS_GW_ADDRESS=$(kubectl get svc -n kgateway-system ai-gateway -o jsonpath="{.status.loadBalancer.ingress[0]['hostname','ip']}")
echo $INGRESS_GW_ADDRESSNow, send a request to the AI Gateway along the /openai path that you previously configured in the HTTPRoute. Behind the scenes, AI Gateway forwards this request to the OpenAI provider model in the order of priority that you set up in the Backend.
curl -v "$INGRESS_GW_ADDRESS:8080/openai" -H content-type:application/json -d '{
"messages": [
{
"role": "user",
"content": "What is kubernetes?"
}
]}' | jqIn the output, notice that the response is from the gpt-4o model, which is the first model in the priority order from the Backend.
{
"id": "chatcmpl-BFQ8Lldo9kLC56S1DFVbIonOQll9t",
"object": "chat.completion",
"created": 1743015077,
"model": "gpt-4o-2024-08-06",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Kubernetes is an open-source container orchestration platform designed to automate the deployment, scaling, and management of containerized applications. Originally developed by Google, it is now maintained by the Cloud Native Computing Foundation (CNCF).\n\nKubernetes provides a framework to run distributed systems resiliently. It manages containerized applications across a cluster of machines, offering features such as:\n\n1. **Automatic Bin Packing**: It can optimize resource usage by automatically placing containers based on their resource requirements and constraints while not sacrificing availability.\n\n2. **Self-Healing**: Restarts failed containers, replaces and reschedules containers when nodes die, and kills and reschedules containers that are unresponsive to user-defined health checks.\n\n3. **Horizontal Scaling**: Scales applications and resources up or down automatically, manually, or based on CPU usage.\n\n4. **Service Discovery and Load Balancing**: Exposes containers using DNS names or their own IP addresses and balances the load across them.\n\n5. **Automated Rollouts and Rollbacks**: Automatically manages updates to applications or configurations and can rollback changes if necessary.\n\n6. **Secret and Configuration Management**: Enables you to deploy and update secrets and application configuration without rebuilding your container images and without exposing secrets in your stack configuration and environment variables.\n\n7. **Storage Orchestration**: Allows you to automatically mount the storage system of your choice, whether from local storage, a public cloud provider, or a network storage system.\n\nBy providing these functionalities, Kubernetes enables developers to focus more on creating applications, while the platform handles the complexities of deployment and scaling. It has become a de facto standard for container orchestration, supporting a wide range of cloud platforms and minimizing dependencies on any specific infrastructure.",
"refusal": null,
"annotations": []
},
"logprobs": null,
"finish_reason": "stop"
}
],
...
}Conclusion
Nice job! You tried out prioritizing models to prepare for failover by creating a kgateway Backend and a couple Gateway API resources. With kgateway’s resiliency features on set up, your AI workloads can bounce back fast in the face of unexpected failures.